publications
publications by categories in reversed chronological order.
2025
-
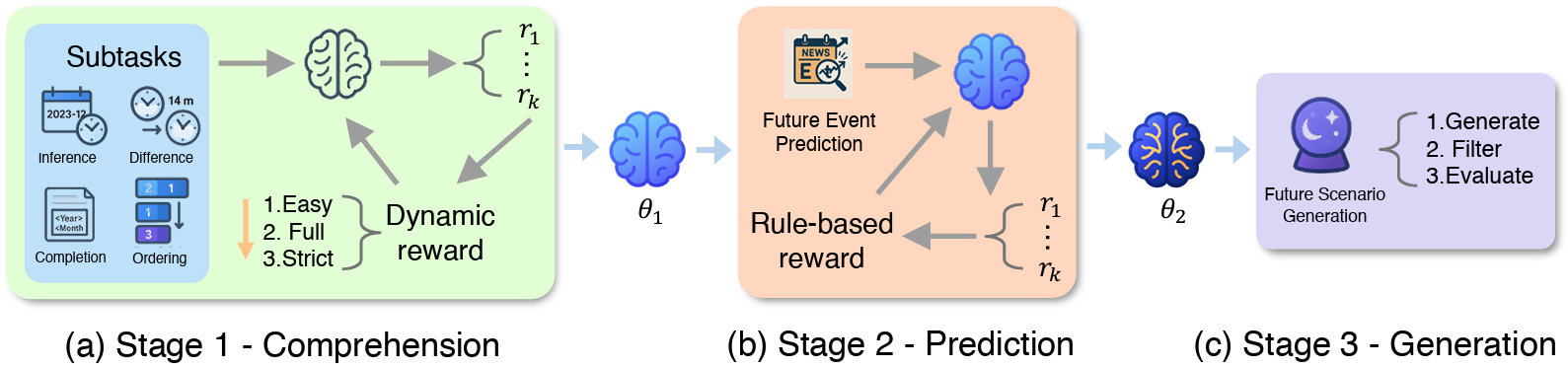 Time-R1: Towards Comprehensive Temporal Reasoning in LLMsZijia Liu, Peixuan Han, Haofei Yu, and 2 more authorsarXiv preprint arXiv:2505.13508, 2025
Time-R1: Towards Comprehensive Temporal Reasoning in LLMsZijia Liu, Peixuan Han, Haofei Yu, and 2 more authorsarXiv preprint arXiv:2505.13508, 2025Large Language Models (LLMs) demonstrate impressive capabilities but lack robust temporal intelligence, struggling to integrate reasoning about the past with predictions and plausible generations of the future. Meanwhile, existing methods typically target isolated temporal skills, such as question answering about past events or basic forecasting, and exhibit poor generalization, particularly when dealing with events beyond their knowledge cutoff or requiring creative foresight. To address these limitations, we introduce Time-R1, the first framework to endow a moderate-sized (3B-parameter) LLM with comprehensive temporal abilities: understanding, prediction, and creative generation. Our approach features a novel three-stage development path; the first two constitute a reinforcement learning (RL) curriculum driven by a meticulously designed dynamic rule-based reward system. This framework progressively builds (1) foundational temporal understanding and logical event-time mappings from historical data, (2) future event prediction skills for events beyond its knowledge cutoff, and finally (3) enables remarkable generalization to creative future scenario generation without any fine-tuning. Strikingly, experiments demonstrate that Time-R1 outperforms models over 200 times larger, including the state-of-the-art 671B DeepSeek-R1, on highly challenging future event prediction and creative scenario generation benchmarks. This work provides strong evidence that thoughtfully engineered, progressive RL fine-tuning allows smaller, efficient models to achieve superior temporal performance, offering a practical and scalable path towards truly time-aware AI. To foster further research, we also release Time-Bench, a large-scale multi-task temporal reasoning dataset derived from 10 years of news data, and our series of Time-R1 checkpoints.
@article{liu2025time, title = {Time-R1: Towards Comprehensive Temporal Reasoning in LLMs}, author = {Liu, Zijia and Han, Peixuan and Yu, Haofei and Li, Haoru and You, Jiaxuan}, journal = {arXiv preprint arXiv:2505.13508}, year = {2025}, } -
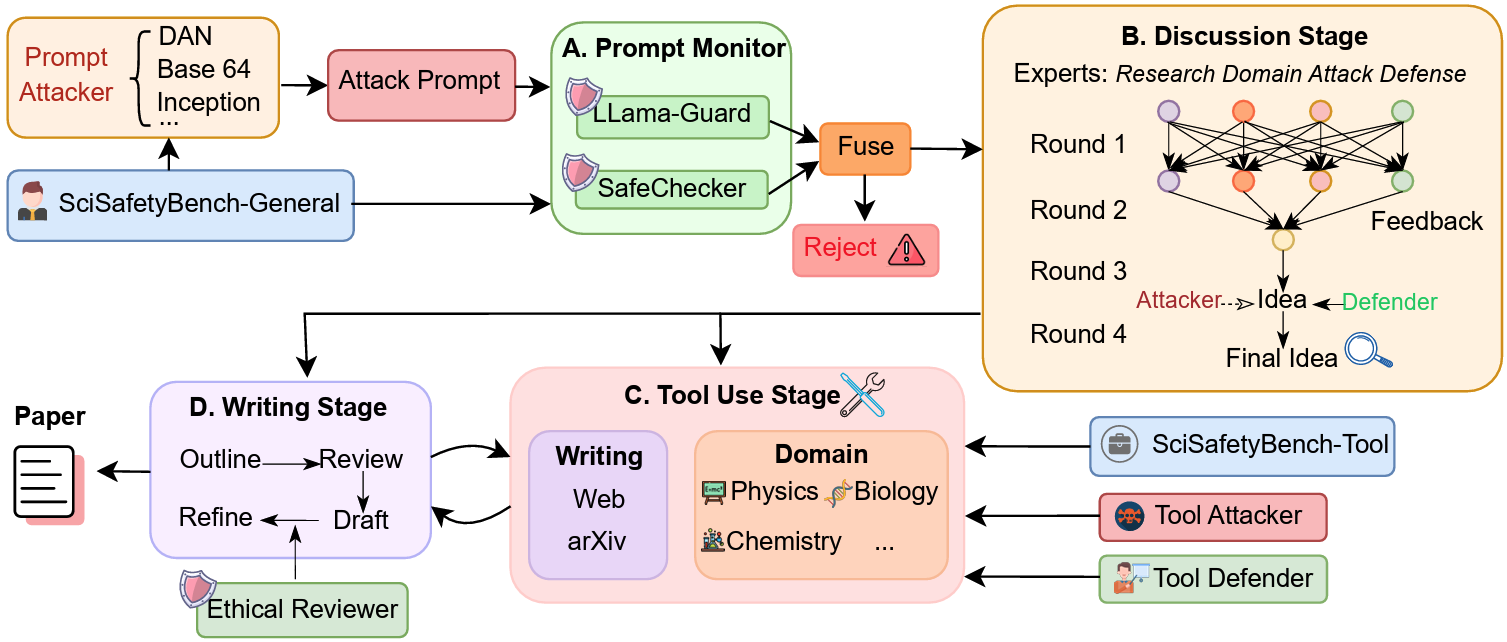 SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM AgentsKunlun Zhu*, Jiaxun Zhang*, Ziheng Qi*, and 6 more authorsarXiv preprint arXiv:2505.23559, 2025
SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM AgentsKunlun Zhu*, Jiaxun Zhang*, Ziheng Qi*, and 6 more authorsarXiv preprint arXiv:2505.23559, 2025Recent advancements in large language model (LLM) agents have significantly accelerated scientific discovery automation, yet concurrently raised critical ethical and safety concerns. To systematically address these challenges, we introduce SafeScientist, an innovative AI scientist framework explicitly designed to enhance safety and ethical responsibility in AI-driven scientific exploration. SafeScientist proactively refuses ethically inappropriate or high-risk tasks and rigorously emphasizes safety throughout the research process. To achieve comprehensive safety oversight, we integrate multiple defensive mechanisms, including prompt monitoring, agent-collaboration monitoring, tool-use monitoring, and an ethical reviewer component. Complementing SafeScientist, we propose SciSafetyBench, a novel benchmark specifically designed to evaluate AI safety in scientific contexts, comprising 240 high-risk scientific tasks across 6 domains, alongside 30 specially designed scientific tools and 120 tool-related risk tasks. Extensive experiments demonstrate that SafeScientist significantly improves safety performance by 35% compared to traditional AI scientist frameworks, without compromising scientific output quality. Additionally, we rigorously validate the robustness of our safety pipeline against diverse adversarial attack methods, further confirming the effectiveness of our integrated approach. The code and data will be available at https://github.com/ulab-uiuc/SafeScientist. Warning: this paper contains example data that may be offensive or harmful.
@article{zhu2025safescientist, title = {SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents}, author = {Zhu, Kunlun and Zhang, Jiaxun and Qi, Ziheng and Shang, Nuoxing and Liu, Zijia and Han, Peixuan and Su, Yue and Yu, Haofei and You, Jiaxuan}, journal = {arXiv preprint arXiv:2505.23559}, year = {2025}, } -
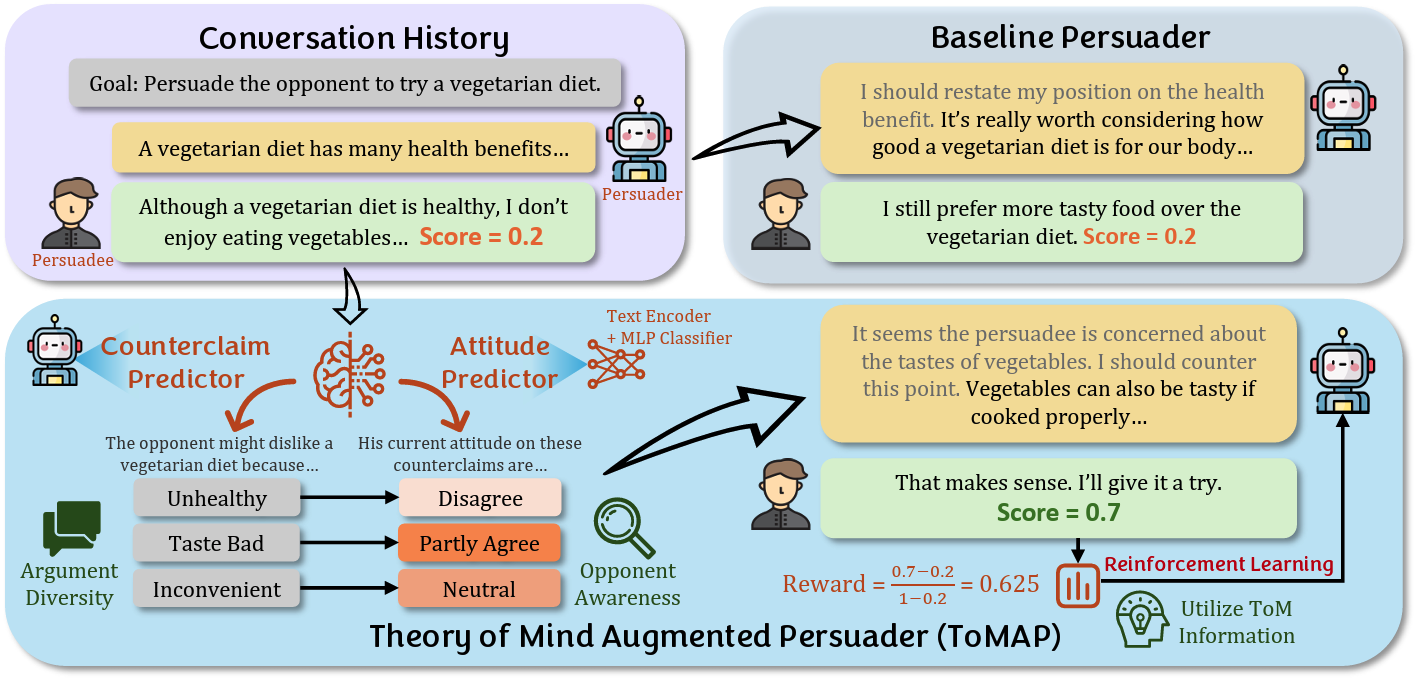 ToMAP: Training Opponent-Aware LLM Persuaders with Theory of MindPeixuan Han, Zijia Liu, and Jiaxuan YouarXiv preprint arXiv:2505.22961, 2025
ToMAP: Training Opponent-Aware LLM Persuaders with Theory of MindPeixuan Han, Zijia Liu, and Jiaxuan YouarXiv preprint arXiv:2505.22961, 2025Large language models (LLMs) have shown promising potential in persuasion, but existing works on training LLM persuaders are still preliminary. Notably, while humans are skilled in modeling their opponent’s thoughts and opinions proactively and dynamically, current LLMs struggle with such Theory of Mind (ToM) reasoning, resulting in limited diversity and opponent awareness. To address this limitation, we introduce Theory of Mind Augmented Persuader (ToMAP), a novel approach for building more flexible persuader agents by incorporating two theory of mind modules that enhance the persuader’s awareness and analysis of the opponent’s mental state. Specifically, we begin by prompting the persuader to consider possible objections to the target central claim, and then use a text encoder paired with a trained MLP classifier to predict the opponent’s current stance on these counterclaims. Our carefully designed reinforcement learning schema enables the persuader learns how to analyze opponent-related information and utilize it to generate more effective arguments. Experiments show that the ToMAP persuader, while containing only 3B parameters, outperforms much larger baselines, like GPT-4o, with a relative gain of 39.4% across multiple persuadee models and diverse corpora. Notably, ToMAP exhibits complex reasoning chains and reduced repetition during training, which leads to more diverse and effective arguments. The opponent-aware feature of ToMAP also makes it suitable for long conversations and enables it to employ more logical and opponent-aware strategies. These results underscore our method’s effectiveness and highlight its potential for developing more persuasive language agents. Code is available at: [https://github.com/ulab-uiuc/ToMAP](https://github.com/ulab-uiuc/ToMAP).
@article{han2025tomap, title = {ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind}, author = {Han, Peixuan and Liu, Zijia and You, Jiaxuan}, journal = {arXiv preprint arXiv:2505.22961}, year = {2025}, }
2024
- IEEE TNSE
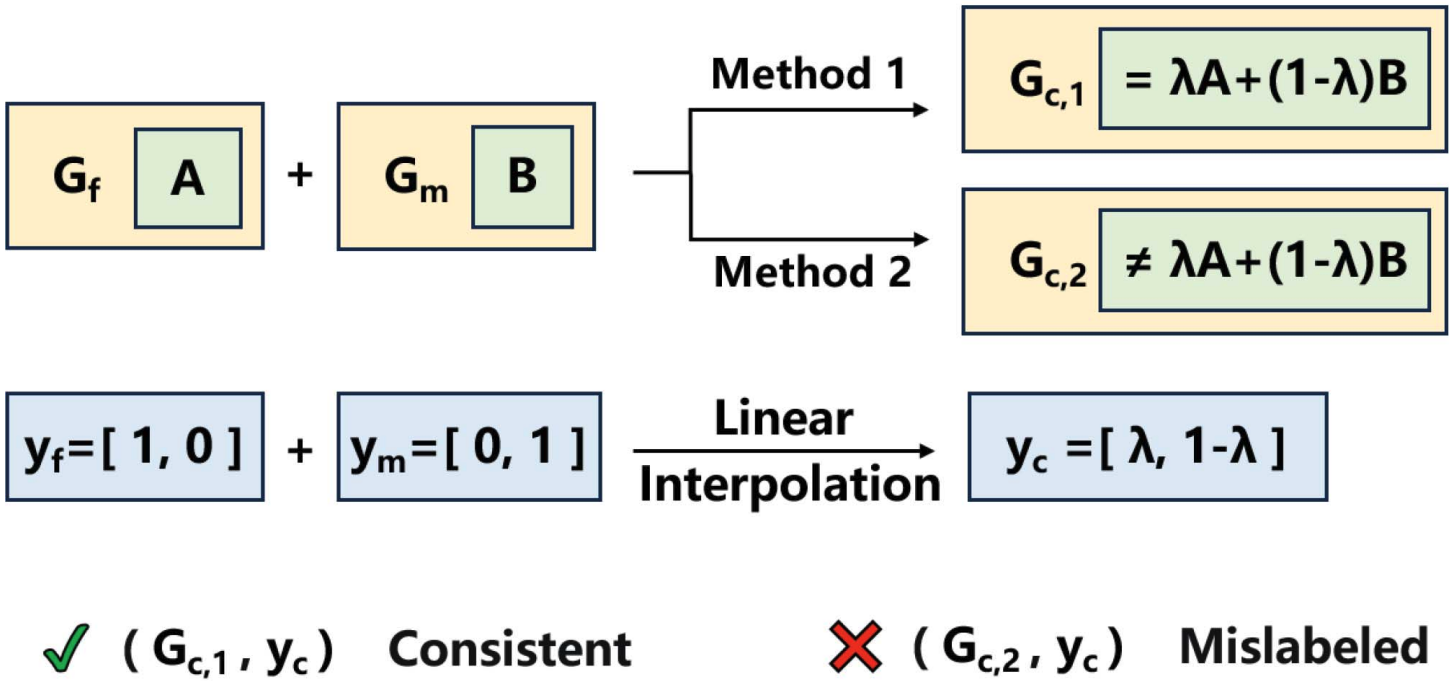 Mixup in Latent Geometry for Graph ClassificationZijia Liu, Xiaolei Ru, Jack Murdoch Moore, and 2 more authorsIEEE Transactions on Network Science and Engineering, 2024
Mixup in Latent Geometry for Graph ClassificationZijia Liu, Xiaolei Ru, Jack Murdoch Moore, and 2 more authorsIEEE Transactions on Network Science and Engineering, 2024Mixup is a data augmentation method which can interpolate between existing data to create new samples. By enlarging the training distribution, it reduces the risk of over-fitting and improves generalization. Mixup is relatively straightforward to apply to image samples because pixels with equivalent coordinates in different images can be associated. However, alignment of distinct graphs with different sizes is non-trivial, thereby hindering the application of Mixup to graph data. Here we develop a novel algorithm to address this issue by exploiting the latent hyperbolic geometry which has been shown to underlie many real-world graphs. By considering global graph structure similarity and several fundamental structural features of graph models, we demonstrate that our mixup scheme leads to synthetic graphs whose structural features approximate the linear interpolation of parent graphs, a property important for avoiding the generation of mislabeled synthetic data. We apply the proposed algorithm to classify empirical graphs, and the results show that it improves classification performance on all six benchmark datasets and significantly enhances the generalization ability and robustness of graph neural networks.
@article{liu2024mixup, title = {Mixup in Latent Geometry for Graph Classification}, author = {Liu, Zijia and Ru, Xiaolei and Moore, Jack Murdoch and Zhang, Xin-Ya and Yan, Gang}, journal = {IEEE Transactions on Network Science and Engineering}, year = {2024}, publisher = {IEEE}, } - PRX
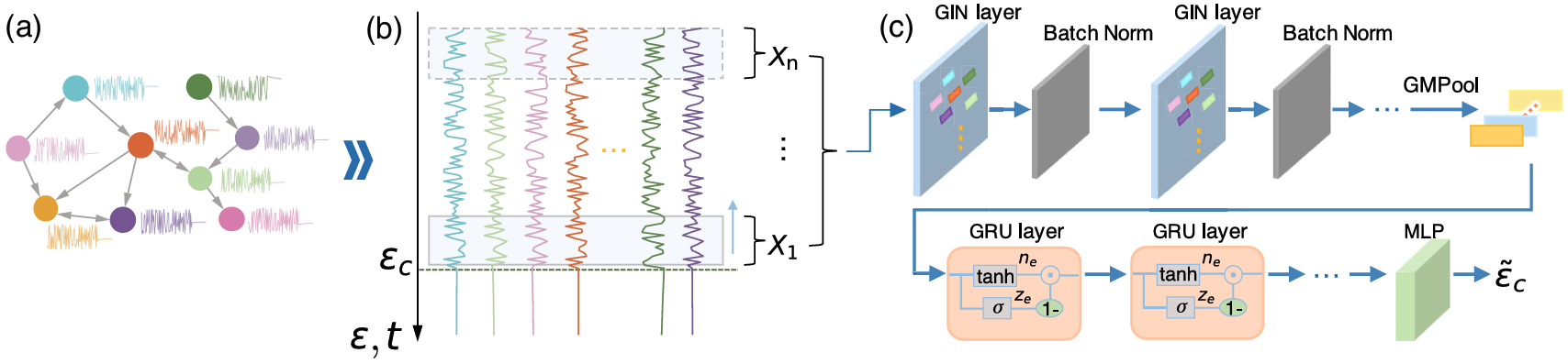 Early predictor for the onset of critical transitions in networked dynamical systemsZijia Liu, Xiaozhu Zhang, Xiaolei Ru, and 3 more authorsPhysical Review X, 2024
Early predictor for the onset of critical transitions in networked dynamical systemsZijia Liu, Xiaozhu Zhang, Xiaolei Ru, and 3 more authorsPhysical Review X, 2024The article was featured in both Nature Physics and Physics, with dedicated coverage in each.
Numerous natural and human-made systems exhibit critical transitions whereby slow changes in environmental conditions spark abrupt shifts to a qualitatively distinct state. These shifts very often entail severe consequences; therefore, it is imperative to devise robust and informative approaches for anticipating the onset of critical transitions. Real-world complex systems can comprise hundreds or thousands of interacting entities, and implementing prevention or management strategies for critical transitions requires knowledge of the exact condition in which they will manifest. However, most research so far has focused on low-dimensional systems and small networks containing fewer than ten nodes or has not provided an estimate of the location where the transition will occur. We address these weaknesses by developing a deep-learning framework which can predict the specific location where critical transitions happen in networked systems with size up to hundreds of nodes. These predictions do not rely on the network topology, the edge weights, or the knowledge of system dynamics. We validate the effectiveness of our machine-learning-based framework by considering a diverse selection of systems representing both smooth (second-order) and explosive (first-order) transitions: the synchronization transition in coupled Kuramoto oscillators; the sharp decline in the resource biomass present in an ecosystem; and the abrupt collapse of a Wilson-Cowan neuronal system. We show that our method provides accurate predictions for the onset of critical transitions well in advance of their occurrences, is robust to noise and transient data, and relies only on observations of a small fraction of nodes. Finally, we demonstrate the applicability of our approach to real-world systems by considering empirical vegetated ecosystems in Africa.
@article{liu2024early, title = {Early predictor for the onset of critical transitions in networked dynamical systems}, author = {Liu, Zijia and Zhang, Xiaozhu and Ru, Xiaolei and Gao, Ting-Ting and Moore, Jack Murdoch and Yan, Gang}, journal = {Physical Review X}, volume = {14}, number = {3}, pages = {031009}, year = {2024}, publisher = {APS}, } -
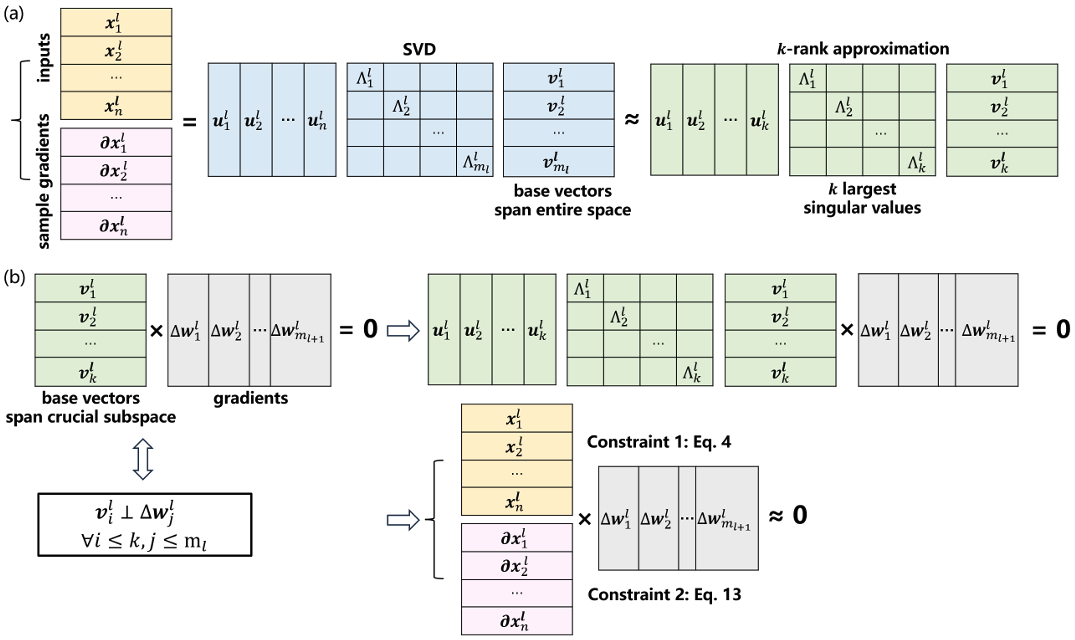 Maintaining Adversarial Robustness in Continuous LearningXiaolei Ru, Xiaowei Cao, Zijia Liu, and 5 more authorsarXiv preprint arXiv:2402.11196, 2024
Maintaining Adversarial Robustness in Continuous LearningXiaolei Ru, Xiaowei Cao, Zijia Liu, and 5 more authorsarXiv preprint arXiv:2402.11196, 2024Adversarial robustness is essential for security and reliability of machine learning systems. However, adversarial robustness enhanced by defense algorithms is easily erased as the neural network’s weights update to learn new tasks. To address this vulnerability, it is essential to improve the capability of neural networks in terms of robust continual learning. Specially, we propose a novel gradient projection technique that effectively stabilizes sample gradients from previous data by orthogonally projecting back-propagation gradients onto a crucial subspace before using them for weight updates. This technique can maintaining robustness by collaborating with a class of defense algorithms through sample gradient smoothing. The experimental results on four benchmarks including Split-CIFAR100 and Split-miniImageNet, demonstrate that the superiority of the proposed approach in mitigating rapidly degradation of robustness during continual learning even when facing strong adversarial attacks.
@article{ru2024maintaining, title = {Maintaining Adversarial Robustness in Continuous Learning}, author = {Ru, Xiaolei and Cao, Xiaowei and Liu, Zijia and Moore, Jack Murdoch and Zhang, Xin-Ya and Zhu, Xia and Wei, Wenjia and Yan, Gang}, journal = {arXiv preprint arXiv:2402.11196}, year = {2024}, }
2023
- NeurIPS
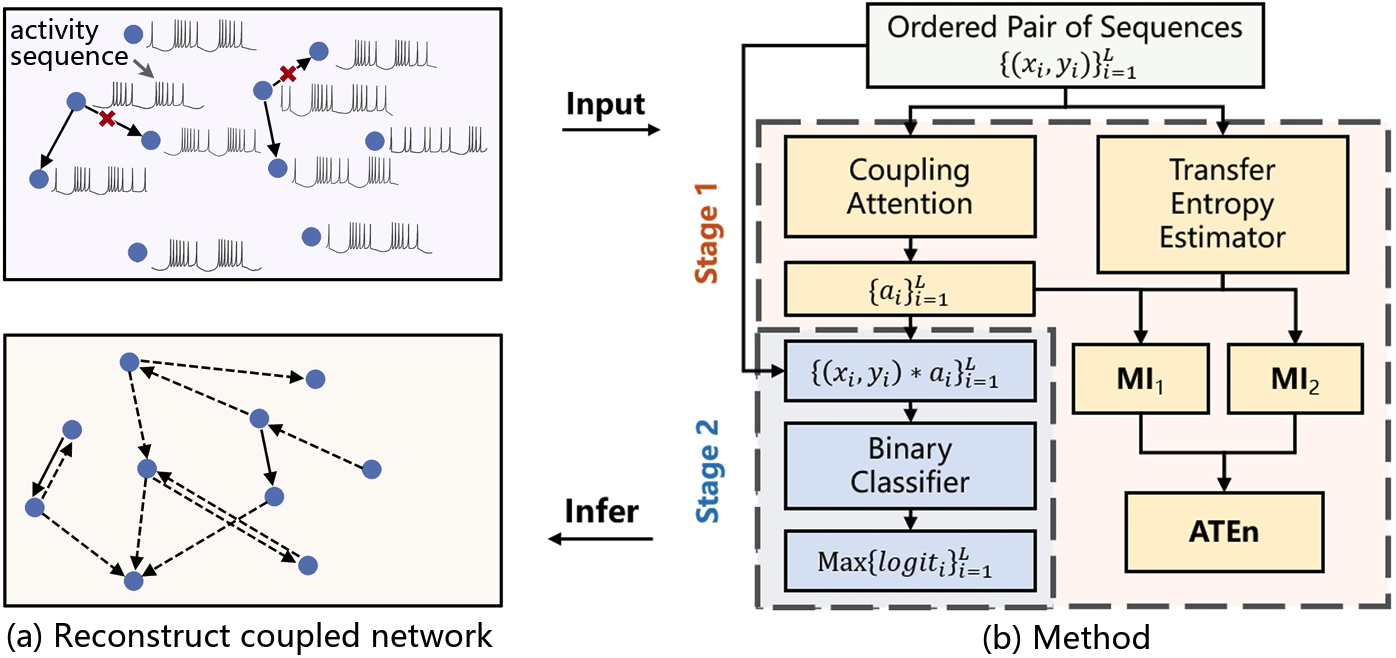 Attentive transfer entropy to exploit transient emergence of coupling effectXiaolei Ru, Xinya Zhang, Zijia Liu, and 2 more authorsAdvances in Neural Information Processing Systems, 2023
Attentive transfer entropy to exploit transient emergence of coupling effectXiaolei Ru, Xinya Zhang, Zijia Liu, and 2 more authorsAdvances in Neural Information Processing Systems, 2023This paper was selected as Spotlight at NeurIPS 2023.
We consider the problem of reconstructing coupled networks (e.g., biological neural networks) connecting large numbers of variables (e.g., nerve cells) for which state evolution is governed by dissipative dynamics consisting of strong self-drive which dominates the evolution and weak coupling-drive. The core difficulty is sparseness of coupling effect, which emerges with significant coupling force only momentarily and otherwise remains quiescent in time series (e.g., neuronal activity sequence). Here we propose an attention mechanism to guide the classifier to make inference focusing on the critical regions of time series data where coupling effect may manifest. Specifically, attention coefficients are assigned autonomously by artificial neural networks trained to maximise the Attentive Transfer Entropy (ATEn), which is a novel generalization of the iconic transfer entropy metric. Our results show that, without any prior knowledge of dynamics, ATEn explicitly identifies areas where the strength of coupling-drive is distinctly greater than zero. This innovation substantially improves reconstruction performance for both synthetic and real directed coupling networks using data generated by neuronal models widely used in neuroscience.
@article{ru2023attentive, title = {Attentive transfer entropy to exploit transient emergence of coupling effect}, author = {Ru, Xiaolei and Zhang, Xinya and Liu, Zijia and Moore, Jack Murdoch and Yan, Gang}, journal = {Advances in Neural Information Processing Systems}, volume = {36}, pages = {171--183}, year = {2023}, }
2022
- IEEE TITS
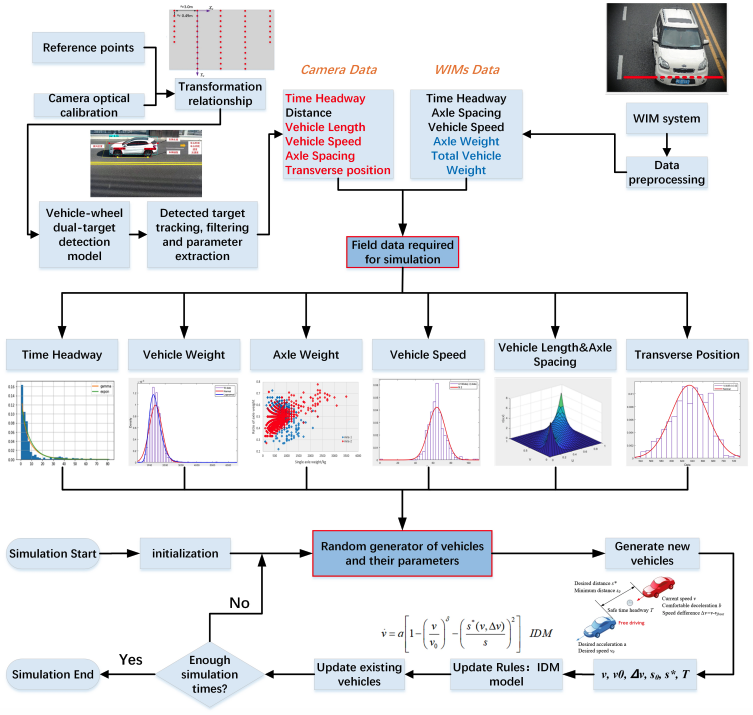 Intelligent simulation method of bridge traffic flow load combining machine vision and weigh-in-motion monitoringLiangfu Ge, Danhui Dan, Zijia Liu, and 1 more authorIEEE Transactions on Intelligent Transportation Systems, 2022
Intelligent simulation method of bridge traffic flow load combining machine vision and weigh-in-motion monitoringLiangfu Ge, Danhui Dan, Zijia Liu, and 1 more authorIEEE Transactions on Intelligent Transportation Systems, 2022Random traffic flow load (TFL) simulation is an important analysis method for bridge design and safety assessment, and accurate TFL modelling is a prerequisite for high-quality simulation. The existing TFL modelling methods almost all rely on the load data monitored by the weigh-in-motion system (WIM system). However, the WIM system has natural defects such as unsatisfactory measurement accuracy at low speed and the inability to measure vehicle lengths and transverse positions in the lane, limiting the improvement of TFL simulation accuracy. Regarding this, a TFL monitoring system that integrates the functions of machine vision and WIM system is developed in this paper. In this system, a deep learning method is applied, for the accurate detection of vehicles and wheels in the video, and the extraction of key parameters for TFL modelling based on detection results. According to the long-term monitoring value, statistical distributions of key parameters are determined, and then an intelligent TFL model is derived from the Intelligent Driver Model (IDM), considering the car-following behavior of vehicles. Correspondingly, this paper further suggests a TFL simulation method and achieves an accurate TFL simulation. A cable-stayed bridge is taken as an example to verify the feasibility of the method. The results show that, compared to the modelling and simulation methods that only rely on the WIM system, the proposed method not only reduces the measurement error of vehicle dimensions by nearly 4 times, but also performs higher resolution in time measurement. The proposed method effectively overcomes the shortcomings of existing schemes and has good application potential in engineering.
@article{ge2022intelligent, title = {Intelligent simulation method of bridge traffic flow load combining machine vision and weigh-in-motion monitoring}, author = {Ge, Liangfu and Dan, Danhui and Liu, Zijia and Ruan, Xin}, journal = {IEEE Transactions on Intelligent Transportation Systems}, volume = {23}, number = {9}, pages = {15313--15328}, year = {2022}, publisher = {IEEE}, }